c++中的memory order问题
在C++中,我们使用atomic时会发现相关操作都有一个可选的参数std::memory_order,本文就分析以下这几种memory_order的用法,以方便大家写出更加高效的多线程代码。
首先确定的是,memory_order这件事情只存在于atomic中。如果使用的不是atomic,那么可以认为代码本身就不是线程安全的,自然也没必要考虑内存模型了。
例如考虑以下代码:
1 | |
很显然这段代码中对于counter的操作是没什么线程安全可言的,毕竟++这种操作不具有原子性。很显然我们可以考虑更新一下实现:
1 | |
fech_add的第一个参数很好理解,就是原子地+1,但是第二个参数比较让人费解,std::memory_order_relaxed。一般情况下我们在别的语言里操作atomic的时候都不会有这种参数,为什么在c++里有呢?
例如
golang中是atomic.AddInt64,java中是incrementAndGet。
首先给出结论,std::memory_order_relaxed顾名思义是内存序的一种。如果不指定默认使用的内存序是memory_order_seq_cst,它的效果和go以及java里的那些接口是几乎一致的。
CPU指令乱序执行
为了说明内存序的用处,先复习一个基本的概念:CPU指令的乱序执行。这个概念如下图所示: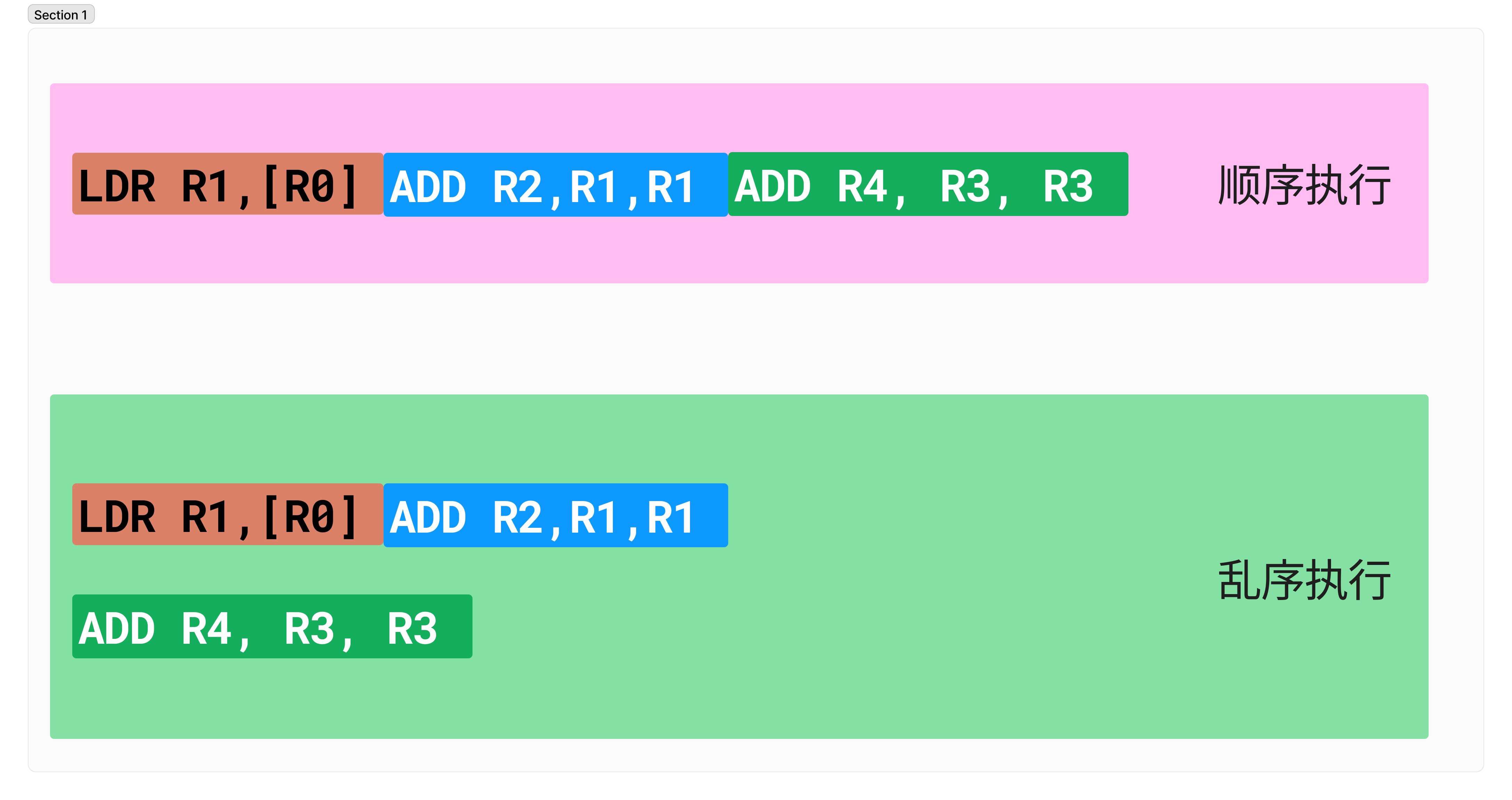
如果两条指令之间没有依赖,那么CPU可能不会保证指令之间的顺序性,而是如图所示把一些指令提前执行充分利用CPU上的逻辑单元。在非并发的情况下不会有什么问题,但是对于并发的代码就会带来一些bug,考虑以下代码:
1 | |
在样例代码中,consume负责消费一些事件,在监听到flag被设置成1的时候,quit在代码退出的时候调用,先负责把一些还没有发送出去的事件都发送了,再设置flag。其中std::memory_order_relaxed用于模拟允许CPU指令乱序的情况。
显然,flag的读写和q的读写是没有数据依赖的,遇上在单线程中不会出问题的指令重排,在多线程中就出现了问题:在quit中,store指令可能被调度到了生产剩余事件的指令之前,导致consume在load到flag=1时,剩余事件还没有完全生产完,最终导致最终q中还残留了数据
所以我们知道了第一个内存序
std::memory_order_relaxed,对于指令乱序完全不负责,因此比较适合一些单纯的计数器。
std::memory_order_release用于发布
memory_order_release确保对共享变量的读写操作不会因为重排导致在当前原子操作之后发生。也就是相当于对于上例的quit函数,人为地插入了一个屏障(barrier):
1 | |
请注意,这里提到的屏障指的是所有内存操作,不单独指对于flag的,对于q的操作也生效。因此,我们可以保证q.push_back一定会发生在flag.store之前。
所以memory_order_release特别适合用来做类似“发布”的逻辑:我们往线程共用的内存中写入了一些数值,并且在最后”发布“给其他的线程,memory_order_release能保证其他线程看到atomic变量改变的时候,也一定能看到共用的内存的变化。
std::memory_order_acquire用于接受
相反地,std::memory_order_acquire用于确保对共享变量的读写都不会因为重排到当前原子操作之前发生。以上例中的consume为例:
1 | |
同样的,这里的内存操作也是所有的内存操作。因此counter++也不会被重排到flag.store之前。能够确保它不会在退出的时候还错误地自增。
因此memory_order_acquire很适合用于“监听”某些变量的变化:在监听到变量才能执行的内存操作不会被重排到之前。
可以看出一般memory_order_release和memory_order_acquire在多线程编程中都是成对使用,用于构建“生产者-消费者”模型或者“监听-发布”这样的逻辑。
std::memory_order_acq_rel我全都要
memory_order_acq_rel可以理解为memory_order_release和memory_order_acquire的集合体,相当于以下的逻辑:
1 | |
可以说是最严格的内存序。但是要注意的是,它禁止的是它前后的指令重排不能跨越它,不代表在它之前的那些指令自己不能发生重排。
这么做肯定对于性能影响也是最大的,但是在其他语言中默认的atomic操作就类似这样(C++的默认内存序也是用它),因此也不用过多担忧,在吃不准应该用哪个内存序的时候用它一定不会带给你额外的bug。
std::memory_order_consume 容易搞错的内存序
memory_order_consume类似memory_order_acquire,都是用于读操作。所以先说一个结论:任何用memory_order_consume的变量操作都建议替换成memory_order_acquire。memory_order_consume的不同之处在于它对于指令重排的限制仅限于和对应的atomic相关的内存操作。考虑以下代码:
1 | |
因为*p2是关联到atomic操作的语句,因此*p2不会被重排到(1)之前,所以assert肯定成立。但是(3)和atomic操作不关联,因此是有可能重排到(1)之前的。所以assert可能不过。
因此memory_order_consume相比于memory_order_acquire限制更小,所以对于内存的影响更小。但是因为这种语义暧昧容易混用的情况,在c++20中已经移除了。所以在这里建议统一使用memory_order_acquire。
总结
通过上文的分析,我们可以发现内存序主要通过限制本线程的对于内存操作的指令重排,使得其他线程见到的内存状态处于一个有序的状态。相比于其他语言,C++留给用户指定atomic操作时的内存序的途径,因此更有助于因地制宜在正确的结果和性能开销方面做出平衡。
总结几个内存序的使用场合:
memory_order_relaxed
不限制任何内存重排,适用于简单的计数器以及非关键性的逻辑。
memory_order_release和memory_order_acquire
最常用的组合,用于实现“生产者-消费者”或者“监听-发布”。
memory_order_acq_rel
memory_order_release和memory_order_acquire的组合体,最多的性能开销换来最严格的内存序。如果你不知道该用啥,那就用它。一点点性能开销换来没有额外bug是很值得的,要知道多线程的内存处理带来的bug简直是生命燃烧机。
memory_order_consume
别用。c++标准里都要去掉的东西,别头铁了。